Le Data Lake, un enjeu majeur pour les entreprises
L’émergence du concept de data lake s’est accélérée grâce à la convergence du besoin de plateformes fédératrices dans les entreprises et de nouveaux moyens techniques et économiques apportés par le big data. Avec le déploiement de la collecte de données, les grands groupes industriels et entreprises ont appris à gérer le big data, cependant un problème de taille s’est posé : comment extraire ces données de façon pertinente? Les data lakes ont ainsi commencé à apparaître.
Qu’est ce que le data lake ?
Terme inventé par James Dixon, directeur de la technologie chez Penthao. Techniquement, le Data Lake permet de rassembler les données structurées, semi-structurées, non structurées et même binaires comme les fichiers audios et vidéos, puis de les traiter dans leur état initial.
Comment gérer un « lac de données »
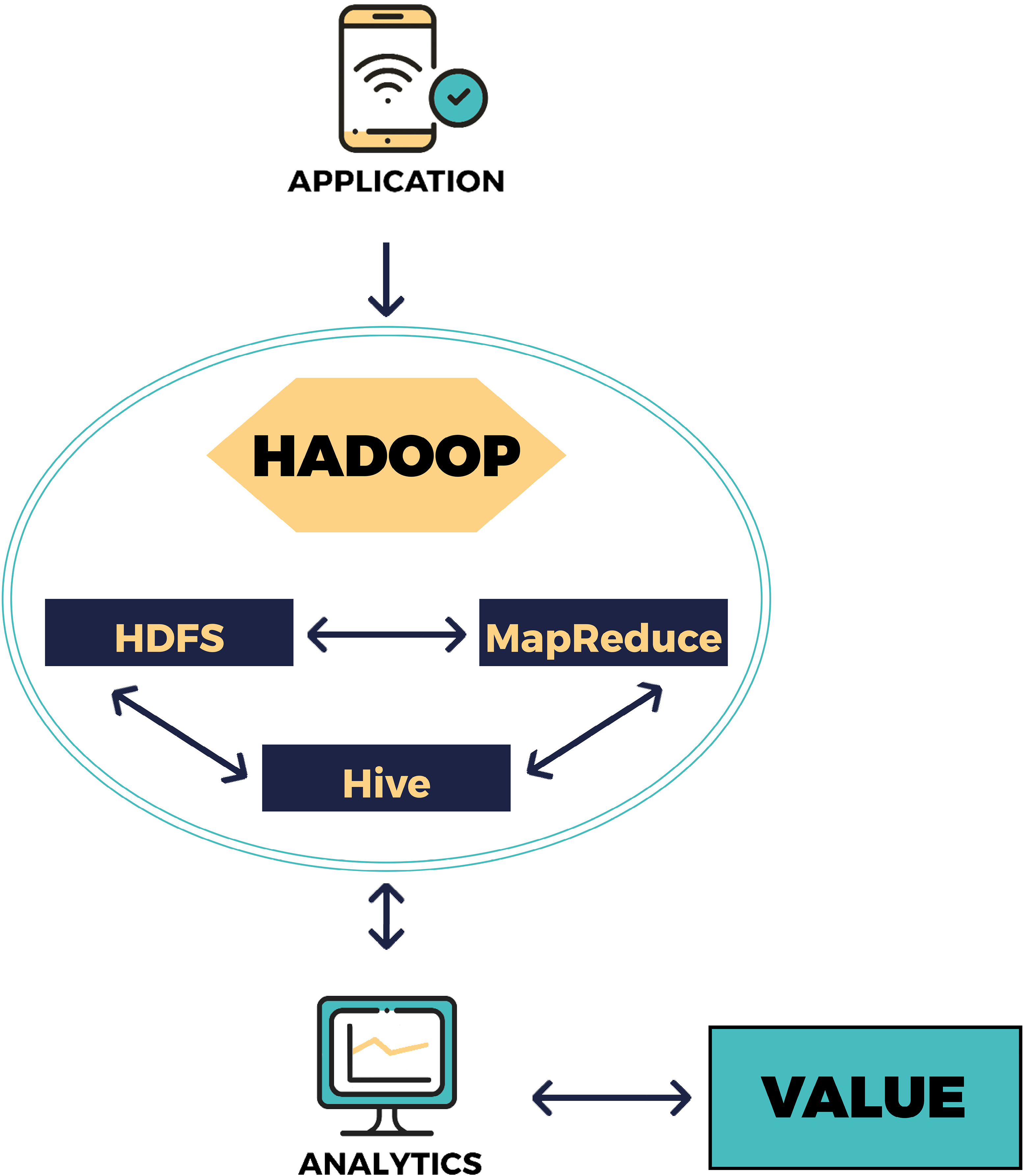
Il est aisé de comprendre la gestion du « lac de données » si on le compare avec le système précédent, le datawarehouse. Le système ETL (extract – transform – load) qui était opérationnel pour un datawarehouse est remplacé par un système ELT (extract – load – transform). La donnée est donc stockée à l’état brut, les développeurs sont moins soumis à la contrainte technique et la donnée est plus complète que dans le système précédent. Trois outils essentiels ont permis cette évolution : le stockage objet, le « schema on read » et Hadoop.
Le stockage objet
Dans le cadre du data lake, le format de donnée stockée n’est plus “fichier” mais “objet”. Les avantages sont nombreux mais on en identifie un principal : le coût réduit par rapport aux serveurs classiques car le stockage objet permet une grande scalabilité.
Schema On Read
Le système du « schema on read » diffère du « schema on write » utilisé dans les datawarehouse. Lorsque la donnée est stockée, elle est transformée dans un format pratique pour son traitement. Cela permet de gagner du temps et le fichier est de meilleure qualité mais il a perdu des informations, on parle de « schema on write ». Dans le cadre du data lake, nul besoin de définir le format avant de le stocker puisqu’il est choisi au moment de la lecture, on parle de « schema on read ».
Hadoop
Apache Hadoop est le principal outil open source utilisé pour le stockage de données en « lac de données ». Il absorbe tous les formats et il est capable d’interagir avec les systèmes traditionnels (Dataiku, Python, tableau…). Hadoop est donc la condition sine qua non à l’existence du data lake.
Le data lake, à quelles fins analytiques ?
En pratique, il est possible d’extraire 4 grands axes analytiques utiles aux entreprises, institutions et collectivités.
Analyse descriptive
Grâce aux données, l’entreprise obtiendra des informations descriptives liées au produit. L’état, l’environnement et le fonctionnement du produit qui fournit des données pourra donc être connu ce qui permet son amélioration.
Analyse diagnostique
L’analyse diagnostique est pertinente lorsqu’il y a une défaillance du produit. Si l’analyse des données issues du data lake fait remonter des baisses de performance ou des dysfonctionnements, l’entreprise peut rappeler le produit ou améliorer la série suivante.
Analyse prédictive
Grâce à l’analyse diagnostique, il est possible de créer une analyse prédictive. Lorsqu’un schéma est reconnu avant une panne, il est donc possible de prédire un problème imminent.
Analyse prescriptive
Essentielle sur le terrain, cette analyse permet d’identifier les mesures à prendre pour améliorer les résultats ou corriger d’éventuelles défaillances.
Le data lake, solution d’avenir ?
Avec le développement des objets connectés, il y a fort à parier que le data lake et son outil phare Hadoop vont continuer de se développer. Encore fallait-il avoir la technologie pour le faire de manière pertinente, c’est aujourd’hui chose faite. Les applications pour les entreprises sont exponentielles, les experts stockage capables de créer des systèmes en data Lakes ont de beaux jours devant eux !
